



🎬 JoyPix AI|AI 数字人与对口型视频创作平台|自研 Motion-2 对口型模型+40+ 头像风格+10 秒语音克隆+40+ 视频模板 免费体验/订阅制
官网/网页工具地址:点击访问
📌 一、基础信息概述
JoyPix AI 是一款以 AI 数字人与对口型视频创作为核心的在线平台,以「让故事讲述更简单与有趣」为核心理念。平台自研 Motion-2 对口型模型——与市面上仅同步嘴唇的 AI 不同,Motion-2 还能根据音频精准调整头部姿态、身体动作和微表情,实现无与伦比的真实感和精准度。Motion-2 支持持久的身份锁定——无论输入是一分钟视频片段还是一张照片,人物的面部、光线和风格能在无限帧中保持一致;并支持 Motion-2-Dialog 双人对口型功能,单个视频中创建两个角色的动态对话。JoyPix 集成多款顶级 AI 视频生成器——Veo 3.1、Sora 2、Wan 2.5/2.6、Vidu Q2、Seedance 等。提供照片对口型(支持宠物)、头像生成器(40+ 风格,油化/水彩/动漫/3D 卡通等)、一站式视频生成、40+ 视频生成模板、免费语音克隆(10 秒语音样本)、文本转语音(40+ 语言和口音)等全套工具。支持构建 AI 数字人实时交互。总部位于日本东京。提供 API 接入支持。
🎯 产品定位
定位为 AI 数字人与对口型视频创作平台,以「简单有趣地创作动画说话头像」为核心理念。面向内容创作者、数字人播客/主持人制作者、社交媒体运营者、游戏玩家、教育/培训内容制作人、电商营销人员等需要快速生成 AI 数字人/对口型视频/头像的用户。核心解决传统数字人制作需大量视频训练数据、对口型效果机械不自然、多角色对话需独立处理、头像风格单一等痛点。
💪 核心优势
- 🎭 自研 Motion-2 对口型模型:不仅同步嘴唇,还能根据音频精准调整头部姿态、身体动作和微表情,无与伦比的真实感
- 🔒 持久身份锁定:不论输入是一分钟视频还是一张照片,人物面部/光线/风格在无限帧中保持一致
- 👥 双人对口型 Dialog:单个视频中创建两个角色的动态对话,每个角色完美同步自己的音轨
- 🎨 头像生成器 40+ 风格:普通照片一键变艺术 AI 图片,油化/水彩/动漫/3D 卡通等
- 🗣️ 免费语音克隆:10 秒语音样本即可克隆任意声音,支持多语言/多情感
- 🎬 40+ 视频模板:无需输入提示词,随选即用快速创作
- 🆓 免费体验:所有功能均可免费体验
- 🐾 支持宠物对口型:狗狗等动物也能对口型说话
🎬 适配场景
- 🎭 AI 数字人播客/主持人:上传照片+音频生成数字人口播/播客视频,Motion-2 驱动自然表情和姿态
- 👥 双人对口型对话:Motion-2-Dialog 创建两个角色的动态对话,适合访谈/辩论/故事类内容
- 🎨 个性化头像创作:照片一键变 40+ 风格的艺术头像
- 🐾 宠物对口型娱乐:宠物照片+音频生成趣味宠物口播视频
- 🗣️ 多语言配音+语音克隆:10 秒语音样本克隆,40+ 语言配音
- 🎬 快速视频生成:40+ 视频模板随选即用,集成 Veo 3.1/Sora 2/Wan 2.5 等模型
👥 核心受众
- 内容创作者与自媒体博主
- 数字人播客/视频主持人制作人
- 社交媒体运营者与品牌营销
- 游戏玩家与虚拟形象爱好者
- 教育/培训内容制作人
- 需要 AI 数字人和对口型视频的跨境电商卖家
🎪 适配定位
专注 AI 数字人与对口型视频创作赛道。核心强项是「自研 Motion-2 对口型模型(头姿+身体+微表情+嘴唇同步,超越同级)+ 持久身份锁定(一帧照片即可保持面部/光线/风格一致)+ 双人对口型 Dialog(单视频双角色对话)+ 头像生成器 40+ 风格 + 10 秒免费语音克隆 + 40+ 视频模板」;主打从数字人播客到双人对话到宠物对口型的 AI 数字人视频创作。
🧩 二、核心功能清单
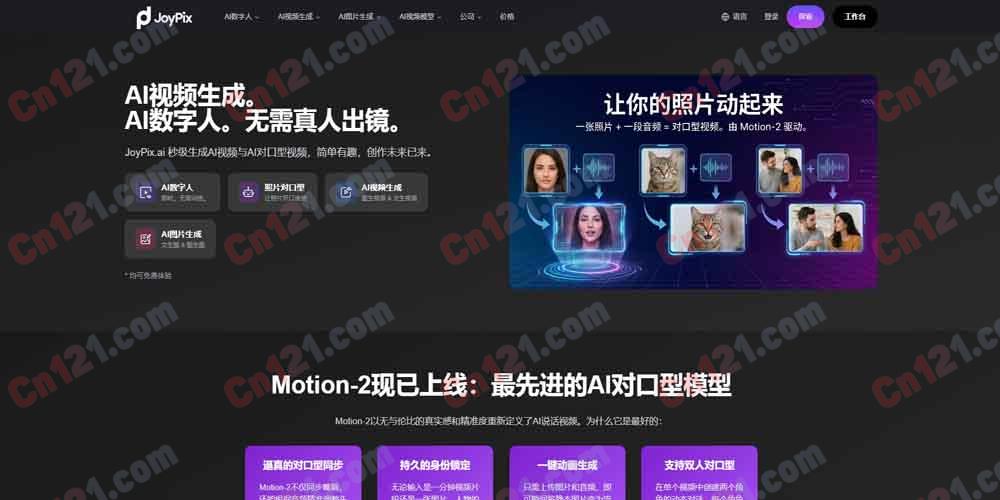
🎭 Motion-2 对口型模型(核心)
JoyPix 自研的旗舰 AI 对口型模型,以无与伦比的真实感和精准度重新定义 AI 说话视频。区别于市面上仅同步嘴唇的 AI,Motion-2 不仅能同步嘴唇,还能根据音频精准调整头部姿态、身体动作和微表情,实现无缝真实效果。其核心能力包括三方面:逼真的对口型同步(头部姿态+身体动作+微表情多维度协同);持久的身份锁定(无论输入是一分钟视频还是一张照片,人物的面部、光线和风格能在无限帧中保持一致);一键动画生成(上传图片和音频即可瞬间将静态照片变为流畅的说话或唱歌视频)。
👥 Motion-2-Dialog 双人对口型
在单个视频中创建两个角色的动态对话,每个角色都能完美同步自己的音轨。由 Motion-2-Dialog 驱动,适合播客访谈、辩论故事、教育对话等多角色场景。
🎨 头像生成器
普通照片一键变艺术 AI 图片,支持油画、水彩、动漫、3D 卡通等 40+ 风格。适合社交媒体头像、游戏形象、个人 IP 打造。
🗣️ 免费语音克隆
只需 10 秒语音样本即可克隆任意声音,并支持多语言、多情感自然发声。无需大量训练数据。
💬 文本转语音
支持 40+ 语言和口音,轻松生成多语种配音。
🎬 一站式视频生成器
集成多款顶级 AI 视频生成器:Veo 3.1(Google)、Sora 2(OpenAI)、Wan 2.5/2.6(阿里)、Vidu Q2(生数科技)、Seedance(字节) 等,一站式轻松创作专业视频。
🎪 40+ 视频生成模板
40+ 种视频生成模板,随选即用,无需输入提示词,快速视频创作。
🐾 宠物对口型
不仅支持人类照片,还支持宠物(狗狗等)对口型说话,趣味性强。
补充说明:JoyPix 的核心差异化壁垒为「自研 Motion-2 对口型模型(头部姿态+身体动作+微表情+嘴唇同步多维协同,超越同级)+ 持久身份锁定(一帧照片即可保持无限帧一致)+ Motion-2-Dialog 双人对口型 + 40+ 头像风格生成 + 10 秒免费语音克隆 + 40+ 视频模板」,区别于仅同步嘴唇或需大量训练数据的其他 AI 数字人方案。
💰 三、免费与收费规则(仅供参考以官网最新为准)
JoyPix 采用免费体验 + 订阅制的计费模式。所有功能均可免费体验。
| 版本类型 | 收费标准 | 权益与限制 |
|---|---|---|
| 🆓 免费版 | 免费 | 所有功能均可免费体验基础版本。适合初次体验和效果测试。 |
| 🚀 订阅版 | 订阅制 | 解锁更高生成配额、更高分辨率、无水印等高级功能。 |
真实规则说明:
- 所有功能均可免费体验(官网标注)
- 视频生成成功才扣费,失败不收费
- 支持 API 接入
- 具体订阅方案请访问官网升级页面查看
- 所有计费规则以 JoyPix 官方最新公示为准
🖥️ 四、支持使用方式与运行说明
🚀 1. 支持使用方式
JoyPix 为云端 Web 平台,通过浏览器即可使用。
标准使用流程(Motion-2 对口型): 注册 JoyPix 账号 → 免费体验 → 选择「照片对口型」→ 上传照片(支持人物/宠物) → 上传或录制音频(或选择文字输入→TTS 生成语音) → Motion-2 模型自动分析音频语义 → 精准调整头部姿态+身体动作+微表情 → 生成对口型视频 → 预览下载
双人对口型流程: 选择 Motion-2-Dialog → 上传两个角色的照片(或从已有头像中选择)→ 分别输入/上传各自的音频 → AI 在单视频中创建双角色动态对话
⚙️ 2. 运行说明
- 🆓 均可免费体验
- 🎭 Motion-2:头部姿态+身体动作+微表情多维同步(自研)
- 👥 Motion-2-Dialog:单视频双角色对话
- 🎨 40+ 头像风格(油画/水彩/动漫/3D 卡通等)
- 🗣️ 10 秒语音克隆
- 💬 40+ 语言 TTS
- 🎬 集成模型:Veo 3.1/Sora 2/Wan 2.5/2.6/Vidu Q2/Seedance 等
- 🎪 40+ 视频模板
- 🐾 支持宠物对口型
- 🔗 API 开放
- 🏢 日本东京
- ⚠️ 仅通过官方渠道可保障功能完整与数据安全
📍 五、产品核心优势与适用人群落地场景
| 使用场景 | 用户类型 | 传统工具痛点 | JoyPix 落地优势 |
|---|---|---|---|
| 🎭 AI 数字人播客/主持人 | 内容创作者 | 传统 AI 仅同步嘴唇,表情僵硬不自然 | Motion-2 头部姿态+身体动作+微表情多维协同,真实感远超同级;持久身份锁定保持无限帧一致 |
| 👥 双人对口型对话 | 播客/访谈创作者 | 双人对话需分别单独处理再手动合成 | Motion-2-Dialog 单视频中双角色动态对话,每个角色完美同步自己的音轨 |
| 🎨 个性化头像创作 | 社交媒体用户 | 头像风格单一,需专业设计才能多风格化 | 照片一键变 40+ 风格 AI 头像,油画/水彩/动漫/3D 卡通随选 |
| 🐾 宠物对口型娱乐 | 社交媒体运营 | 宠物对口型需专业后期处理 | 直接上传宠物照片+音频,Motion-2 驱动宠物对口型说话 |
| 🗣️ 多语言配音+克隆 | 跨境电商/教育 | 多语言配音需专业配音员,成本高 | 10 秒语音样本克隆,40+ 语言 TTS 多情感自然发声 |
| 🎬 快速视频模板创作 | 短视频创作者 | 每次写 Prompt 耗时费力 | 40+ 视频模板随选即用,无需输入提示词 |
⚠️ 六、官方使用须知
- JoyPix AI 核心聚焦 AI 数字人与对口型视频创作平台。
- 自研 Motion-2 对口型模型(头部姿态+身体动作+微表情多维同步)+ Motion-2-Dialog(双人对口型)。
- 所有功能均可免费体验,视频生成成功才扣费。
- 集成多款顶级 AI 视频生成器(Veo 3.1/Sora 2/Wan 2.5/2.6/Vidu Q2/Seedance)。
- 提供头像生成器(40+ 风格)、语音克隆(10 秒)、TTS(40+ 语言)、40+ 视频模板。
- 支持宠物对口型。
- 支持 API 接入。
- 总部位于日本东京江东区有明。
- 仅通过官方渠道可保障功能完整与数据安全。
❓ 七、常见问题解答
| 问题分类 | 具体问题 | 官方解答 |
|---|---|---|
| 🎭 产品类 | JoyPix 是什么? | AI 数字人与对口型视频创作平台,自研 Motion-2 对口型模型。 |
| 🆓 付费类 | 可以免费使用吗? | 可以,所有功能均可免费体验。高级功能需订阅。 |
| 🎭 Motion-2 是什么? | 自研最先进的 AI 对口型模型,头姿+身体+微表情+嘴唇同步。 | |
| 👥 双人对口型怎么用? | Motion-2-Dialog,单视频双角色动态对话。 | |
| 🗣️ 语音克隆需要多久? | 10 秒语音样本即可克隆。 | |
| 🎨 头像支持多少风格? | 40+ 风格(油画/水彩/动漫/3D 卡通等)。 | |
| 📱 API 有吗? | 有,API 文档在 /openapi/。 |
🔍 八、替代方案与对比参考
1. 云端 AI 产品竞品对比分析
| 云AI工具 | 核心优势 | 相比 JoyPix 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🎬 HeyGen | AI 数字人行业领先,140+ 语言,SOC 2 企业级 | 无自研 Motion-2 级对口型模型(头部姿态+身体+微表情多维同步),无 Motion-2-Dialog 双人对口型,无 40+ 头像风格生成器,无宠物对口型 | https://www.heygen.com |
| 🎬 D-ID | AI 数字人对口型精准,企业级 | 无可比 Motion-2 多维同步和身份锁定能力,无 40+ 头像风格,无宠物对口型 | https://www.d-id.com |
| 🎬 Synthesia | 140+ 数字人,企业级视频平台 | 无自研 Motion-2 多维度对口型,无双人对口型 Dialog,无 头像风格生成器 | https://www.synthesia.io |
| 🎬 Vidnoz | 1900+ 数字人,2000+ 语音,免费 | Motion-2 多维同步和身份锁定不如 JoyPix,无 40+ 头像风格 | https://www.vidnoz.com |
| 🎬 可灵 AI(快手) | DiT 架构 3.0 视频生成国内领先 | 视频生成为主,对口型和数字人非核心赛道,无 Motion-2 级对口型和头像生成 | https://klingai.com |
| 🎬 JoyPix | Motion-2 多维对口型+Dialog 双人+40+ 头像风格+10 秒语音克隆+40+ 模板+宠物对口型 | 最专注的自研 AI 数字人与对口型视频创作平台 | — |
2. 本地部署方案竞品对比分析
| 本地软件 | 核心优势 | 相比 JoyPix 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🎬 ComfyUI + LivePortrait + Wav2Lip | 开源组合方案:LivePortrait(面部重定向)+Wav2Lip(唇形同步) | 无国产 Motion-2 多维同步(头部姿态+身体动作+微表情),无身份锁定能力,无 40+ 头像风格,无语音克隆/TTS/模板,需 GPU 和技术门槛极高 | https://github.com/comfyanonymous/ComfyUI |
| 🎬 LivePortrait | 开源面部表情/动作重定向 | 仅动作重定向,无端到端对口型/头像/TTS/模板能力 | https://github.com/KwaiVGI/LivePortrait |
| 🎬 Wav2Lip | 开源唇形同步 | 仅嘴唇同步,无头部姿态/身体/微表情能力 | https://github.com/Rudrabha/Wav2Lip |
| 🎬 GPT-SoVITS | 开源语音克隆 | 仅语音克隆,无对口型/头像/视频能力 | https://github.com/RVC-Boss/GPT-SoVITS |
| 🎬 SadTalker | 开源图片对口型视频 | 无 JoyPix 头部姿态/身份锁定/双人对口型能力 | https://github.com/OpenTalker/SadTalker |
3. 通用大模型能力横向评估
| 大模型 | 核心优势 | 相比 JoyPix 短板 | 官网下载渠道网址 |
|---|---|---|---|
| 🔍 GPT-4o (OpenAI) | 多模态理解领先 | 无对口型/数字人/头像能力 | https://chatgpt.com |
| 🔍 Claude (Anthropic) | 长文本理解出色 | 无视频/图像/语音生成能力 | https://claude.ai |
| 🔍 Gemini (Google) | 多模态理解强 | 无对口型/数字人平台 | https://gemini.google.com |
| 🔍 DeepSeek-R1 | 推理能力强 | 无视频/图像/语音能力 | https://chat.deepseek.com |
| 🔍 通义千问 2.5 | 阿里云生态 | 无对口型/数字人平台 | https://tongyi.aliyun.com |
| 🔍 Veo 3.1(Google) | 视频生成质量领先 | JoyPix 已集成 | https://deepmind.google |
4. 模型选型适配场景推荐指南
| 适用场景 | 推荐选型方案 | 选型说明 | 获取渠道网址 |
|---|---|---|---|
| 🎭 AI 数字人播客/主持人 | JoyPix(Motion-2) | 自研多维对口型+身份锁定+双人 Dialog | — |
| 👥 双人对话对口型 | JoyPix(Motion-2-Dialog) | 单视频双角色动态对话 | — |
| 🎨 40+ 风格头像生成 | JoyPix 头像生成器 | 照片一键变 40+ 风格 | — |
| 🐾 宠物对口型 | JoyPix | 宠物照片+音频生成 | — |
| 🏢 企业级 AI 数字人 | HeyGen / Synthesia | 企业级数字人 SOC 2 | https://www.heygen.com |
| 🖥️ 本地自定义 AI 工作流 | ComfyUI | 开源免费,需 GPU 和技术 | https://github.com/comfyanonymous/ComfyUI |
5. 开源模型生态与安全下载渠道
| 渠道平台 | 官方网址 | 渠道核心优势与安全说明 | 适配场景与使用说明 |
|---|---|---|---|
| 🌐 Hugging Face | https://huggingface.co | 全球最大开源模型社区 | 适合下载 LivePortrait/Wav2Lip 等开源对口型模型 |
| 🌐 GitHub | https://github.com | 全球最大代码托管平台 | 适合获取 ComfyUI/LivePortrait 等项目源码 |
| 🇨🇳 阿里魔搭 ModelScope | https://modelscope.cn | 国内官方平台,网络稳定 | 适合国内用户下载中文 AI 模型 |
| 🖥️ Ollama | https://ollama.com | 极简本地部署框架 | 适合本地运行语言模型辅助提示词生成 |
| 🎬 ComfyUI | https://github.com/comfyanonymous/ComfyUI | 开源节点式 AI 工作流 | 适合搭建本地 AI 视频/图像工作流 |
| 🇨🇳 OpenI 启智 | https://openi.pcl.ac.cn | 国内开源 AI 平台 | 适合政企用户开源模型下载和托管 |
6. 开源替代方案与本地自建评估
| 开源方案名称 | 官方网址 | 核心能力说明 | 是否可本地部署 | 与 JoyPix 对比优劣 |
|---|---|---|---|---|
| 🎬 ComfyUI + LivePortrait + Wav2Lip | https://github.com/comfyanonymous/ComfyUI | 组合方案:ComfyUI(工作流)+LivePortrait(面部重定向)+Wav2Lip(唇形同步)+GPT-SoVITS(语音克隆)+FFmpeg(合成) | ✅ 是 | 优势:完全免费开源、可本地运行。劣势:无 Motion-2 多维同步(头部姿态+身体+微表情),无身份锁定(需手动保持各帧一致),无 40+ 头像风格生成器,无 10 秒语音克隆预置工具,无 40+ 视频模板,需 GPU 和技术能力极高 |
| 🎬 LivePortrait | https://github.com/KwaiVGI/LivePortrait | 快手开源面部表情/动作重定向 | ✅ 是 | 劣势:仅动作重定向,无对口型/语音克隆/头像/模板,无可比全链路 |
| 🎬 Wav2Lip | https://github.com/Rudrabha/Wav2Lip | 开源唇形同步 | ✅ 是 | 劣势:仅唇形同步,无头部姿态/身体/微表情能力 |
| 🎬 GPT-SoVITS | https://github.com/RVC-Boss/GPT-SoVITS | 开源语音克隆 | ✅ 是 | 劣势:仅语音克隆,无对口型/头像/视频能力 |
| 🎬 SadTalker | https://github.com/OpenTalker/SadTalker | 开源图片对口型视频 | ✅ 是 | 劣势:仅基础对口型,无多维同步/身份锁定/双人对话能力 |
| 🎬 JoyPix | — | Motion-2 多维对口型+Dialog 双人+40+ 头像风格+10 秒语音克隆+40+ 模板+宠物对口型 | ❌ 云端 | 最专注的自研 AI 数字人与对口型视频创作平台 |
选型建议: JoyPix 在「自研 Motion-2 对口型模型(头部姿态+身体动作+微表情+嘴唇同步多维协同,超越 Wav2Lip 等仅同步嘴唇的方案)+ 持久身份锁定(一帧照片即可在无限帧中保持面部/光线/风格一致)+ Motion-2-Dialog 双人对口型(单视频双角色动态对话)+ 40+ 头像风格生成器(油画/水彩/动漫/3D 卡通等)+ 10 秒免费语音克隆 + 40+ 视频模板 + 宠物对口型」的综合覆盖上,对于需要高质量 AI 数字人/对口型视频的创作者来说是非常专注的选择。开源方案需要组合 LivePortrait(动作重定向)+ Wav2Lip(唇形同步)+ GPT-SoVITS(语音克隆)+ ComfyUI(工作流)+ 手动维护身份一致性等多达 5 个独立项目才能近似替代 JoyPix 的核心功能,但:① 缺少 Motion-2 的多维同步能力——LivePortrait 仅做面部重定向,Wav2Lip 仅做唇形同步,无法在一个模型内实现头部姿态+身体动作+微表情+嘴唇的协同;② 缺少身份锁定——开源方案需手动维护每帧间的一致性;③ 缺少 Motion-2-Dialog 的双人对口型能力;④ 缺少一键式 40+ 头像风格生成器和 40+ 视频模板。对于内容创作者和数字人制作者,JoyPix 的免费版即可体验 Motion-2 核心功能。对于需要本地部署的技术团队,LivePortrait + Wav2Lip + GPT-SoVITS 的组合是可行方案,但需要在多工具整合和身份一致性维护上投入大量人力。